Knowledge
Others
+0
Must-Have Tools for Business Analyst
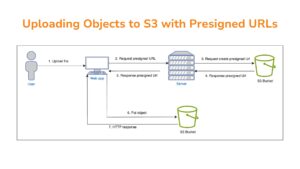
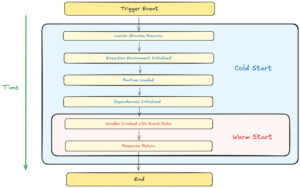
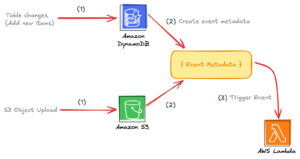
In today’s fast-evolving tech world, working smart has become even more crucial than working hard. In IT environments — and in any modern business — managing a growing amount of complex work can’t rely solely on memory, scattered emails, or individual Excel sheets. One of the most effective ways to boost productivity intelligently is through the use of supporting tools.This isn’t just a trend anymore — it’s quickly becoming the standard in many companies. For Business Analysts (BAs), the right tools don’t just make you more efficient — they make you more professional. Let’s explore some essential tools every BA should have in their toolkit 👇 1. Draw.io A free, intuitive diagramming tool to visualize processes, systems, data, or ideas.It’s ideal for modeling workflows and mapping business logic. Key Features: Free and no registration required — just go to diagrams.net.Flexible storage — save files locally or to Google Drive, OneDrive, GitHub, GitLab.Rich icon library — supports UML, BPMN, flowcharts, network diagrams, and more.UML & BPMN ready — perfect for use cases, activity diagrams, and business flows.Easy collaboration when stored on shared drives.Cross-platform — available on web, desktop, and as a VS Code extension. Limitations: Real-time collaboration isn’t as strong as tools like Figma.Performance may drop with very large or complex diagrams. 2. Miro Miro is an online collaborative whiteboard designed for teams to brainstorm, plan, and visualize ideas in real-time. Key Features: Infinite canvas — visualize projects without space limits.Real-time collaboration — comment, vote, and co-edit instantly.Rich templates — includes user story maps, journey maps, mindmaps, Kanban boards, and wireframes.Integrations — connects with Jira, Confluence, Slack, Teams, Google Drive, and more.Great for mapping processes, use cases, roadmaps, or even UI mockups. Limitations: Free plan limits the number of boards.Large boards with many assets may slow down performance. 3. Trello Trello is a Kanban-based task management tool that helps teams visualize and track progress easily. Key Features: Simple drag-and-drop interface.Highly customizable boards, lists, and cards.Each card can include checklists, attachments, labels, due dates, and assignees.Seamless integration with Google Drive, Slack, Jira, GitHub, and others.Real-time updates across all team members.Works on web, desktop, and mobile. Limitations: Free plan limits the number of integrations (Power-Ups). 4. Jira Jira by Atlassian is the industry-standard project management tool for Agile teams. Key Features: Built for Scrum and Kanban teams.Highly customizable workflows, fields, and automation rules.Transparent tracking of tasks, blockers, and progress.Integrates with hundreds of DevOps, CI/CD, and testing tools.Scales from individual tasks to enterprise-level project portfolios. Limitations: Steep learning curve for beginners.Can be costly for large teams.Requires experienced admins for setup and maintenance.May run slower on large, complex projects. 5. Typescale A handy tool for generating consistent typography systems (font size, line height, spacing) for web or app design. Key Features: Automates type scale creation.Multiple presets and flexible customizations.Preview and export CSS directly.Ensures responsive and accessible typography. Limitations: Not suitable for all design systems or content types.Limited control over detailed responsive behavior. 6. Adobe Color An intuitive color palette generator to create harmonious and accessible color schemes. Key Features: Easy-to-use color wheel with real-time updates.Auto-generates color harmonies based on color theory.Supports HEX, RGB, and CMYK formats.Integrates seamlessly with Adobe tools like Photoshop, Illustrator, and XD.Community palette sharing and inspiration gallery. Limitations: Contrast still needs manual checking for accessibility.Some auto-generated palettes may need manual tweaking.Colors can look different on various screens. 7. Contrast Checker A simple but vital tool to ensure readability and accessibility by checking text and background contrast per WCAG standards. Key Features: Simple interface — input colors and get instant feedback.Ensures compliance with accessibility guidelines.Real-time updates as you adjust colors.Bridges design and development — everyone can validate contrast easily. Limitations: Doesn’t reflect results accurately for complex backgrounds.Doesn’t account for font size, spacing, or user testing conditions. Why Use These Tools? Transparency: Everything — from tasks to deadlines — is clearly tracked. For example, Trello helps answer questions like “Who’s doing what?” and “What’s the current status?”Visualization: Tools like Draw.io help transform abstract logic into clear, easy-to-understand diagrams.Collaboration: Integrating tools like Miro, Jira, or Slack ensures everyone stays aligned and reduces miscommunication. Tips for Getting Started Start small: You don’t need every tool at once. Begin with Jira or Trello, then expand.Build shared habits: Tools only work when the whole team uses them consistently.Learn by doing: Explore free trials and tutorials, then apply them directly in your current projects.Stay updated: Tools evolve fast — keeping up helps you stay ahead. Using tools isn’t just about having more software — it’s about changing the way we work.They make our processes more transparent, our teamwork more seamless, and our output more efficient. For Business Analysts, these tools are not just “nice-to-have” — they’re what turn you from a task executor into a strategic enabler for your team. Read more related articles from SupremeTech!
31/10/2025
157